Universitas Negeri Semarang mulai tahun 2025, menambah koleksi High-performance Computing (HPC) selain NVIDIA DGX Tesla A100, yaitu Supermicro AMD Instinct MI210. Berikut adalah panduan penggunaan server GPU Supermicro AMD Instinct MI210 untuk civitas akademika Universitas Negeri Semarang.

Batasan
- Pengguna fasilitas server GPU Supermicro AMD Instinct MI210 adalah dosen, staff, mahasiswa Universitas Negeri Semarang dan peneliti ataupun masyarakat umum
- Penggunaan fasilitas tunduk pada peraturan penggunaan peralatan dan standar tarif layanan Universitas Negeri Semarang, jika dibutuhkan dan dipergunakan untuk kepentingan komersial
- Penggunaan fasilitas dibatasi menurut kebutuhan komputasi, review atas rencana penggunaan/flowchart aplikasi, dan ketersediaan server/gpu
- Penggunaan fasilitas tunduk pada UU yang berlaku di Indonesia, khususnya UU tentang Informatika dan Transaksi Elektronik, UU tentang Sistem Nasional Ilmu Pengetahuan dan Teknologi, UU tentang Perlindungan Data Pribadi, UU tentang Hak Cipta, UU tentang Pornografi.
Spesifikasi
- 1 buah Supermicro AMD Epyc
- 1 GPU AMD Instinct MI210 64GB VRAM
Pengajuan Akun
Pengajuan akun dan kerjasama penggunaan fasilitas AI Server ini dapat dilakukan menggunakan fasilitas layanan terpadu UNNES secara online di https://helpdesk.unnes.ac.id atau lewat aplikasi MyUNNES (Android/iOS) dengan subjek “Permohonan Fasilitas Penelitian AI Server AMD”.
Prosedur Penggunaan
- Pengguna mendapatkan akun Portainer dan akun VPN untuk dapat mengakses AI Server dengan batasan yang ditetapkan oleh Subdit Sistem Informasi,
- Pengguna melakukan pembuatan container dengan kemampuan GPU menggunakan akun masing-masing sesuai dengan kebijakan dari Subdit Sistem Informasi,
- Pengguna melakukan koneksi ke server lewat jaringan VPN dan login menggunakan akun SSH untuk melakukan proses unggah/unduh file artefak/video/model atau file lainnya jika dibutuhkan,
- Pengguna melakukan eksekusi program/aplikasi dalam lingkungan terbatas di Docker Container yang ditentukan dan disediakan oleh Subdit Sistem Informasi atau image yang sudah diperiksa dan disetujui penggunaannya oleh Subdit Sistem Informasi,
- Pengguna mengunduh hasil program/aplikasi yang dieksekusi oleh Docker Container sesuai kebutuhan
Docker Image yang Telah Disediakan
- AMD ROCm Tensorflow rocm/tensorflow:latest
- AMD ROCm 7.0.x Terminal rocm/rocm-terminal:latest
- AMD ROCM Ubuntu 24.04 with Python 3: rocm/rocm-build-ubuntu-24.04:6.4
- AMD ROCm with Pytorch: rocm/pytorch:latest
- AMD ROCm vLLM: rocm/vllm:latest
Dikarenakan platform AMD Instinct ini menggunakan driver dan ekosistem software ROCm (bukan CUDA seperti GPU NVIDIA), maka ketersediaan tutorial dan container yang menggunakan ROCm ini masih belum terlalu banyak seperti CUDA NVIDIA.
Contoh Penggunaan Server GPU AMD Instinct MI210 UNNES
Mengetahui Driver GPU yang terpasang di Server
Jalankan docker container dengan mengeksekusi perintah berikut:
docker run -it \
--network=host \
--device=/dev/kfd \
--device=/dev/dri \
--ipc=host \
--shm-size 16G \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
rocm/rocm-terminal:latest \
rocm-smiketerangan: perintah diatas akan menggunakan semua GPU yang ada sebagai referensi, dan dieksekusi dalam environment image bawaan dari AMD ROCm yaitu rocm/rocm-terminal, dan aplikasi/tool yang dieksekusi adalah rocm-smi.
contoh hasil eksekusi:

Contoh Menjalankan Code Python dengan kebutuhan Library TensorFlow
Upload source code python yang telah diuji di komputer lokal ke server menggunakan FileZilla ke folder masing-masing, contoh source code python dengan library tensorflow
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
predictions = model(x_train[:1]).numpy()
tf.nn.softmax(predictions).numpy()
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
loss_fn(y_train[:1], predictions).numpy()
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)Kemudian eksekusi dalam container seperti berikut:
docker run -it \
--network=host \
--device=/dev/kfd \
--device=/dev/dri \
--ipc=host \
--shm-size 16G \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-v $(pwd):/workspace \
rocm/tensorflow:latest \
python /workspace/tensorflow-example.pyOutput yang dihasilkan sesuai dengan aplikasi tensorflow-example.py
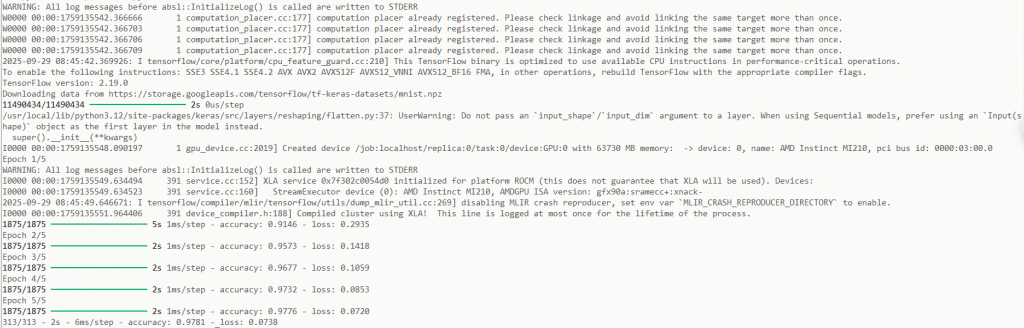
Komputasi Sederhana dengan Pytorch
Silakan tulis sourcecode untuk menghitung MNIST sederhana dengan contoh berikut kemudian eksekusi dalam container rocm-pytorch:
sourcecode:
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-accel', action='store_true',
help='disables accelerator')
parser.add_argument('--dry-run', action='store_true',
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true',
help='For Saving the current Model')
args = parser.parse_args()
use_accel = not args.no_accel and torch.accelerator.is_available()
torch.manual_seed(args.seed)
if use_accel:
device = torch.accelerator.current_accelerator()
else:
device = torch.device("cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_accel:
accel_kwargs = {'num_workers': 1,
'persistent_workers': True,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(accel_kwargs)
test_kwargs.update(accel_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
if __name__ == '__main__':
main()kemudian eksekusi:
docker run -it \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device=/dev/kfd \
--device=/dev/dri \
--group-add video \
--ipc=host \
--shm-size 8G \
-v $(pwd):/workspace \
rocm/pytorch:latest \
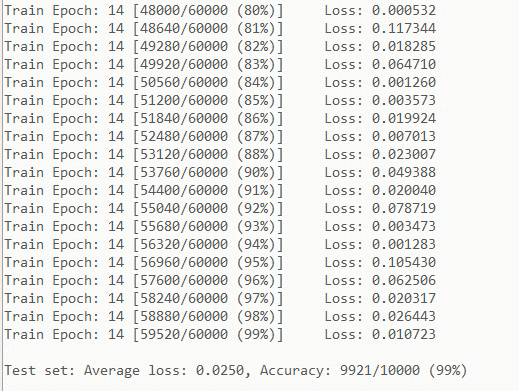
python /workspace/mnist.py
contoh hasil eksekusi script diatas:
Contoh Jupyter Notebook Tensorflow untuk AMD ROCm 7
Buat sebuah folder baru di masing-masing akun. Contoh: /home/namauser/namauser-jupyter-notebook
kemudian buat file dengan nama docker-compose.yml didalamnya:
services:
jupyter-notebook:
image: infraunnes/rocm-jupyternotebook:tensorflow
devices:
- /dev/kfd
- /dev/dri
group_add:
- video
shm_size: 16G
security_opt:
- seccomp=unconfined
- apparmor=unconfined
cap_add:
- SYS_PTRACE
ports:
- "40001:8888"
volumes:
- ./data:/home/jovyan/work
restart: "no"
dengan image docker infraunnes/rocm-jupyternotebook:tensorflow, silakan diganti menyesuaikan kebutuhan. Dengan endpoint http port: 40001 (sesuai dengan port yang diberikan saat pelayanan).
kemudian di console/terminal pada folder tersebut, dan jalankan perintah docker compose up -d:
cd /home/namauser/namauser-jupyter-notebook
chmod 777 /home/namauser/namauser-jupyter-notebook/jupyterdata
docker compose up -ddan login http://10.2.16.99:40001/ atau sesuai dengan instruksi saat layanan helpdesk.